

-
什么是Hibernate
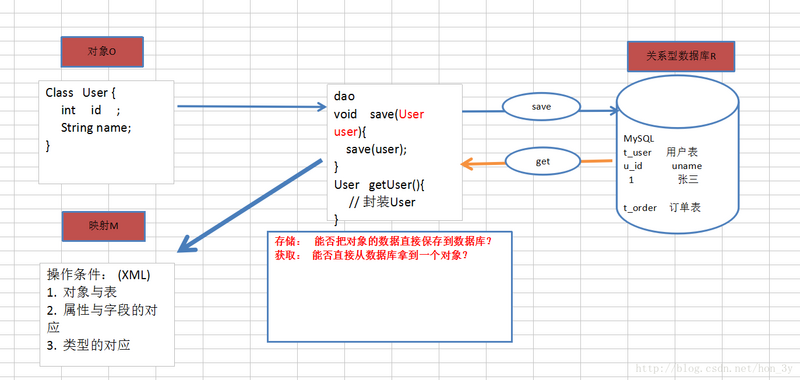
Hibernate是一种ORM框架,全称为 Object_Relative DateBase-Mapping,在Java对象与关系数据库之间建立某种映射,以实现直接存取Java对象
-
什么是ORM
ORM是一种思想
- O代表的是Objcet
- R代表的是Relative
- M代表的是Mapping
ORM->对象关系映射….ORM关注是对象与数据库中的列的关系
-
JavaBean的属性
- JavaBean的属性可以是任意类型,并且一个JavaBean可以有多个属性。每个属性通常都需要具有相应的setter、 getter方法,setter方法称为属性修改器,getter方法称为属性访问器。
- 属性修改器必须以小写的set前缀开始,后跟属性名,且属性名的第一个字母要改为大写,例如,name属性的修改器名称为setName,password属性的修改器名称为setPassword。
- 属性访问器通常以小写的get前缀开始,后跟属性名,且属性名的第一个字母也要改为大写,例如,name属性的访问器名称为getName,password属性的访问器名称为getPassword。
- 一个JavaBean的某个属性也可以只有set方法或get方法,这样的属性通常也称之为只写、只读属性。
Java Bean类实现Serializable接口的原因
- Serializable接口能帮我们做些什么?
如上所述,读写对象会有什么问题呢?比如:我要将对象写入一个磁盘文件而后再将其读出来会有什么问题吗?别急,其中一个最大的问题就是对象引用!举个例子来说:假如我有两个类,分别是A和B,B类中含有一个指向A类对象的引用,现在我们对两个类进行实例化{ A a = new A(); B b = new B(); },这时在内存中实际上分配了两个空间,一个存储对象a,一个存储对象b,接下来我们想将它们写入到磁盘的一个文件中去,就在写入文件时出现了问题!因为对象b包含对对象a的引用,所以系统会自动的将a的数据复制一份到b中,这样的话当我们从文件中恢复对象时(也就是重新加载到内存中)时,内存分配了三个空间,而对象a同时在内存中存在两份,想一想后果吧,如果我想修改对象a的数据的话,那不是还要搜索它的每一份拷贝来达到对象数据的一致性,这不是我们所希望的!
以下序列化机制的解决方案:
1. 保存到磁盘的所有对象都获得一个序列号(1, 2, 3等等)
2. 当要保存一个对象时,先检查该对象是否被保存了
3. 如果以前保存过,只需写入"与已经保存的具有序列号x的对象相同"的标记,否则,保存该对象通过以上的步骤序列化机制解决了对象引用的问题!
在对对象进行实例化的过程中相关注意事项
1. 读取对象的顺序必须与写入的顺序相同
2. 如果有不能被序列化的对象,执行期间就会抛出NotSerializableException异常
3. 序列化时,只对对象的状态进行保存,而不管对象的方法
2. 当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口
4. 当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化,而且会是递归的方式。 (序列化程序会将对象版图上的所有东西储存下来,这样才能让该对象恢复到原来的状态)
5. 如果子类实现Serializable接口而父类未实现时,父类不会被序列化,但此时父类必须有个无参构造方法,否则会抛InvalidClassException异常,因为反序列化时会恢复原有子对象的状态,而父类的成员变量也是原有子对象的一部分。由于父类没有实现序列化接口,即使没有显示调用,也会默认执行父类的无参构造函数使变量初始化
6. 并非所有的对象都可以序列化
至于为什么不可以,有很多原因了,比如:
1. 安全方面的原因,比如一个对象拥有private,public等field,对于一个要传输的对象,比如写到文件,或者进行RMI传输 等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的。
2. 资源分配方面的原因,比如socket,thread类,如果可以序列化,进行传输或者保存,也无法对他们进行重新的资源分配,而且,也是没有必要这样实现。
深入理解
1. 序列化算法透析
Serialization(序列化)是一种将对象以一连串的字节描述的过程;反序列化deserialization是一种将这些字节重建成一个对象的过程。
序列化算法一般会按步骤做如下事情:
- 将对象实例相关类的描述。
- 递归地输出类的超类描述直到不再有超类。
- 从最顶层的超类开始输出对象实例的实际数据值。
2. 序列化ID的问题
serialVersionUID适用于JAVA的序列化机制。简单来说,Java的序列化机制是通过判断类的serialVersionUID来验证版本一致性的。 在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。
3. 序列化存储规则
Java 序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用; 序列化到同一个文件时,如第二次修改了相同对象属性值再次保存时候,虚拟机根据引用关系知道已经有一个相同对象已经写入文件,因此只保存第二次写的引用,所以读取时,都是第一次保存的对象。
4. 多次序列化的问题
在一次的序列化的过程中,ObjectOutputStream 会在文件开始的地方写入一个 Header 的信息到文件中。于是在多次序列化的过程中就会继续在文件末尾(本次序列化的开头)写入 Header 的信息,这时如果进行反序列化的对象的时候会报错:
java.io.StreamCorruptedException: invalid type code: AC
5. 影响序列化
- transient关键字
- writeObject()方法与readObject()方法
- Externalizable接口
- readResolve()方法